Is It SQL?
This started as a simple SQL Server monitoring solution for my clients. The first question I get when applications have issues is “Is It SQL Server?” I wanted a simple monitoring service I could run onsite that would answer that question. It had to be simple enough that a non-DBA could look at it and decide whether to call me.
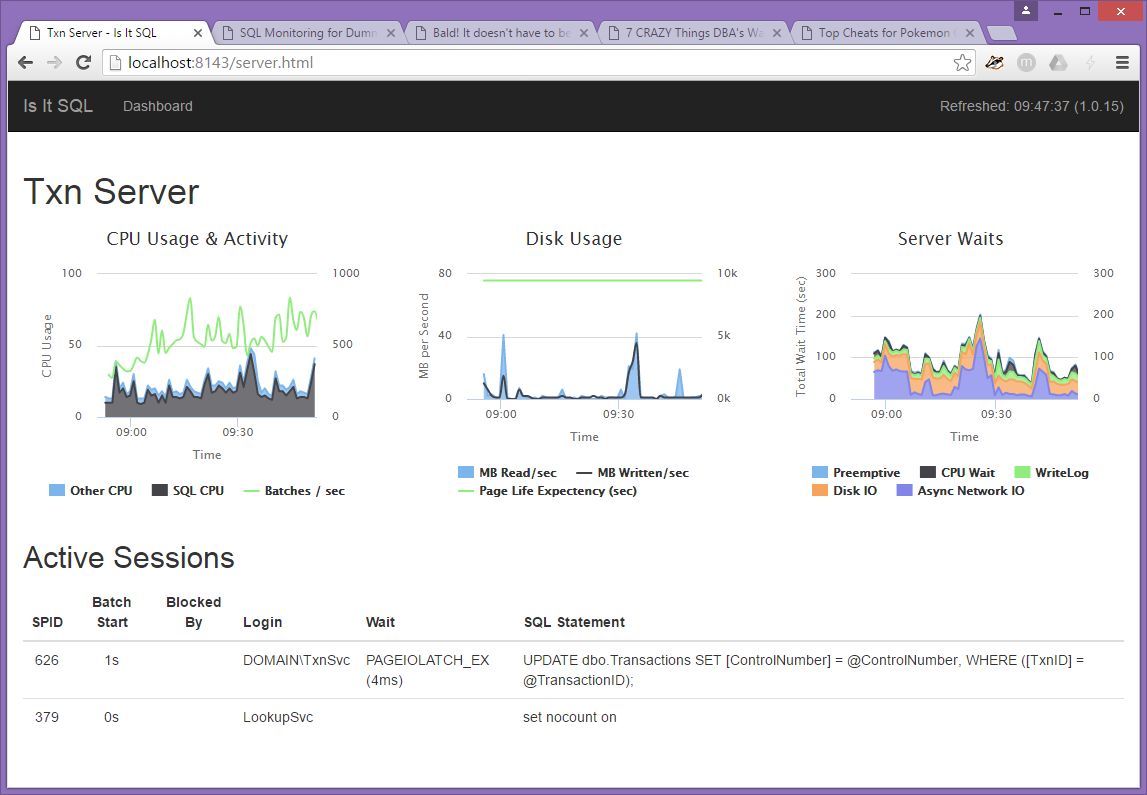
Features
- Supports SQL Server 2008 through SQL Server 2022
- Monitor CPU usage for SQL Server and non-SQL Server tasks
- Capture batch requests per second
- Monitor disk I/O
- Monitor waits
- Show actively running queries
- Capture basic demographic information including version, start time, database sizes, etc.
- Run with no installation or as a service
- Monitor Availability Group and Database Mirroring Status
Requirements
Starting with version 2.0, there are no requirements. It should just work.
Releases
2.0 (20 January 2024)
- Servers can be listed in user editable files. See the documentation in the
optionalfolder. This is hepful if you wantIsItSQLrunning in multiple data centers sharing the same list of servers. - Support non-GUID server keys. If you put the servers in a configuration file, you can have URLs like
/server/db-txn. - Added a Server Connection Detail page at
/server/:server_key/conn - Improve reporting of
tempdbsize - Limit support for Availability Groups to SQL Server 2014 and higher
- Added a Connection Test utility
- The Server Detail page now shows the Windows version. The SQL Server Versions page at
/versionsshows the operating system. Downloading that page as CSV adds the architecture, install date, cores, and memory. - SQL Servers in containers ignore the “other” CPU percentage
- Add a
/memorypage that shows OS memory, SQL Server memory and the amount free - Waits are now polled in real time and only waits on user sessions are displayed by default. See the Features section in the README for more information.
- Switched from the ODBC driver to the native Microsoft GO driver to connect to SQL Server.
- Date and time formatting are improved throughout the application
- Improved the reporting of blocked sessions. This should make it easier to identify the root cause of blocking.
- More polling queries timeout if they get blocked. This is mostly AG queries while adding or removing nodes or databases.
1.7.15 (7 April 2023)
- Most pages and list display the server name if different than the friendly name or how the FQDN
- Add a filter to the home page
- Add ODBC 18 driver and increase priority of newer drivers
- Support optional connection encryption
- The sample PowerShell scripts better support SQL Server Agent with their variable usage
- On the Availability Group list, link back to the primary server
- On the Availability Group list and the database list, display the send and redo queue sizes
- On the databases page, hide any previous log backups for SIMPLE recovery databases
- On the databases page, if an AG database is suspended, list the reason why
- On the home page, increase the refresh from 10 seconds to 30 seconds
- Various bug fixes
- Increase poll timeout from 60 seconds to 120 seconds
- Clean up the menus
- Exclude PWAIT_EXTENSIBILITY_CLEANUP_TASK
- Monitored servers list includes a link to the stats page
1.7.11 (18 August 2022)
- Add Availability Group display names
- Add support for newer ODBC drivers
- Better log file line endings on Windows
- Support
ignoredBackups.csvorignoredBackups.txt - AG page displays Listener names instead of AG names and sorts consistently
- Improve clean up for the NDJSON files that cache metrics
- Add SQL Server 2022 support
- Improve support for SQL Server on Linux
1.7.2 (30 June 2022)
- Update to latest ODBC drivers
- Activity query shows orphaned sessions that are blocking
1.7 (8 May 2022)
- Add a
usagepage that attempts to show Edition and cores used over the last hour. This is a very rough attempt at helping with licensing. This is also downloadable as CSV. - Moved the
tagsubmenus to the top so they are easier to use. They don’t fall off the bottom of the screen any more. - Logging is improved. The configuration files supports enabling TRACE or DEBUG levels of logging. Only retain six previous log files.
- The CPU metrics are incremental. SQL Server records the last minute of CPU usage. This was populating the CPU graph at each poll. However this looked weird when an AG failed over. Now it only adds missing CPU entries.
- Metrics (watis, disk I/O, CPU, etc.) are cached between restarts. They are also displayed as per minute values to better support longer times between polling.
- Better logic to determine the installed date
- If you set a URL for the home page (usually a tag), there is now an “All Servers” link
- Display Send and Receive queues for Availability Groups. The JSON config file supports setting a warning and error threshold for high queue values.
1.4 (9 September 2021)
- Shared Credentials can be defined. These are SQL Server logins and passwords. These can then be assigned to servers. This is useful when a common SQL Server login for monitoring is used. These are stored encrypted in
connections.json. - On the Server List page, you can filter entries
- Added filters to the application error log and the extended events page
- On server lists, display memory percentage as the percentage of the memory cap for the instance. Hovering over the memory field shows the cap the physical memory on the box
- The Extended Events page refreshes every 60 seconds and displays in absolute time instead of relative times
- The settings page allows you to set a URL for the “home page”. This is the link the “Is It SQL” text in the upper left links to. I’ve set this to a tag for key servers such as “/tag/your-tag”. The Tags menu has a link for “All Servers”.
- Supports domain login to edit settings
- Most server displays now use the max memory if it is configured
- A “Versions” page lists all the versions and editions. You can also download this as CSV. The CSV includes cores, edition, and memory so you can do rudimentary licensing validation.
- The Log Events now includes a filter. You can reach this by clicking on the “Refreshed” label on the upper right.
- If servers have the proper extended event session, those events can be filtered. If you haven’t created the Extended Event session, the code to do so is listed on the page. Please see the Extended Events section in this document.
- The Availability Group page now has JSON output. See the About page for the link. This should be suitable for generating alerts.
- Added an Application menu with links to Monitored Servers, Settings, Credentials, the Application Log, and a few other pages
- Added an About page that links to lots of internal pages
- Fixed a bug where ignored backups with trailing spaces wouldn’t ignore
- Added a page to list all database snapshots and their age
1.0.36 (November 10, 2019)
- All the features that were hidden behind beta flags or entering a secret Enterprise code are now available.
- The missing backups page exposes a JSON object with all the missing backups ( http://localhost:8143/backups/json). It’s fairly easy to write a job that emails that out. I wrote one in PowerShell and run it every hour during my “awake” hours.
- The polling is split into two parts. Every 10 seconds, we poll if the server is up and check the health of any availability groups. Then every minute we do a full poll of the server. The pages now refresh every 15 seconds.
- Previously, the polling used a worker pool to poll. That meant a few bad servers could affect polling. Now each server gets its own thread. It uses a little more CPU at the start but quickly evens out. And in the event of an incident (like, I don’t know, losing an entire data center), you still get timely polling on whatever is still out there.
- I added a section at the top of the Availability Groups page that lists one AG per line. I found it easier to read and it’s easy to click down to see the details.
- All error reporting and metrics logging has been removed. There should be no “phone home” functionality in the application at all. The only external access it should need is the HighCharts URL to download the charting library.
- Added support for SQL Server 2019.
1.0.29 (May 15, 2018)
The app better handles “names” that repoint to new instances. For example, an AG listener or static DNS entry that switches to a new instance doesn’t create odd spikes in disk I/O or waits. It also better handles reseting metrics on server restarts.
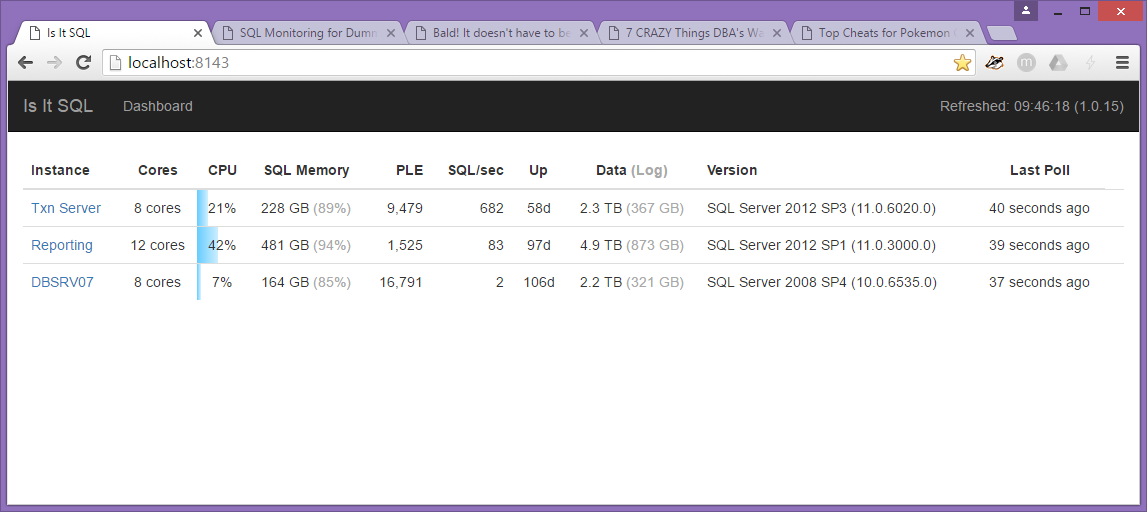
You can choose which servers appear in the dashboard by assigning them a “dashboard” tag. It will show the friendly name you’ve entered and sort by that name.
Backup reporting now reports an AG backup from any node. If you are looking at the database page for a node in an AG, it will show that a backup was completed for that database even if it was done on another node. You can hover over the backup and it will show which node completed the backp, when it was done, and what file it sent the backup to. If you have enabled the Enterprise features, you can see all this on the central backup alerts page.
1.0.28 (September 10, 2017)
- There’s finally some control over what servers appear in the dashboard. Add the “dashboard” tag to three servers and those will appear on the dashboard.
- Better support for multiple Availability Groups hosted by one server.
- Fixed an annoying little bug around the settings page when you have security configured so that you can only save from “localhost”
1.0.27 (July 27, 2017)
- Improved support for tagging. (Sign up for the newsletter to enable tagging)
- Servers now show the total RAM on the server and the amount allocated to SQL Server and the percentage in grey
- Hovering over the cores shows the actual cores used. This very helpful when looking at tags and seeing how many effective cores those servers are using in aggregate.
- Continued to clean up the wait types for SQL Server 2016
1.0.25 (May 11, 2017)
- README.html updated with instructions for this release. Please read it!
- No more servers.txt. This release allows you to add and edit servers.
- Use the app for basic configuration settings such as port, concurrent pollers, and backup alerts thresholds.
1.0.24 (April 6, 2017)
- Add a page to show database servers that don’t have appropriate backups.
- Increased the number of servers that can be polled concurrently
- Cleaned up various wait group names
- Added a page to show a summary of all your servers
- The active sessions will show a percent complete if one is available. Hover over the duration to see it.
1.0.23 (December 13, 2016)
- Include support for availability groups. Is it SQL displays the health of any availability groups it finds. Note: This is an Enteprise feature. Sign up for the mailing list above and I’ll send details on enabling this feature.
- Disk performance now breaks out the MB/sec, IOPS, averge IO size, and average duration over the one minute monitoring period. It does this for reads and writes. This column is also sortable based on the IOPS. This gives an easy way to see which servers are generating the most disk I/O.
- The pages that show a list of servers now include a total line. It totals the disk I/O, SQL batches per second, SQL Server memory, and the size of data and log files. This lets you see the total load you’re placing on your infrastructure across your all servers.
1.0.22 (November 10, 2016)
- Database Mirroring is show in two places.
- It appears on the server page will show any databases that are mirrored.
- Second, there’s a global database mirroring page that will show each mirrored
database across all servers. It will show the status, partner, and send and
receive queue sizes. It also includes a “priority column”. This gives an easy way to
prioritize databases that aren’t online and synchronzied or have a send or receive queue.
This is a beta feature. Sign up for the newsletter and we’ll send instructions on enabling it.
- The log size of database is split out into its own column which makes it sortable.
- Information that is polled in real-time is identified with a cool lightning bolt. Every page refresh will update this data.
- Assorted behind the scenes fixes for perfomance, memory and concurrency.
1.0.20 (September 19, 2016)
- BETA: User-defined tags can be assigned to each server. Please sign up for the newsletter to enable this feature.
- Assorted small bug fixes
1.0.19 (August 30, 2016)
- Hide tasks waiting on BROKER_RECEIVE_WAITFOR from the Active Tasks section
- Added a page to view database details. It shows size, recovery model, compatibility mode, collation, etc.
- The menu bar stays on top when scrolling
- Better error reporting if the port is already in use
- Prioritize the ODBC 13 driver if it’s available
1.0.18 (August 4, 2016)
- Unreachable servers are displayed at the top of every page. Previously some pages didn’t display them.
- Sessions with a wait type of WAITFOR no longer show up as Active Sessions when looking at a server
- Previously the database size included snapshots. Snapshots are no longer included in when computing the data size.
- The default sorting for some columns has been changed to show the higher values first. For example, CPU percentage and database size.
1.0.17 (August 1, 2016)
- The list of servers is sortable by clicking on the header
- Any unreachable server now shows at the top of each page since a page may be sorted in a way that wouldn’t show it.
- If a server is unreachable, it will only log once. It will then log when it becomes reachable.
- Polling should be faster due to more concurrent threads.
- All JavaScript, CSS, HTML, fonts, etc. have been moved inside the executable.
- SQL Server 2005 support is included. Barely.